Por Juliana Vicentini
Pesquisadores da Embrapa e Recod.ai desenvolveram novo modelo capaz de fazer esse tipo de mapeamento com base em séries históricas de imagens de satélite.
O 05 de junho é o Dia Mundial do Meio Ambiente. A data instituída pela ONU é uma oportunidade para mobilizar a sociedade sobre a importância dos recursos naturais. Mas, como saber se eles estão sendo preservados ou degradados? A resposta começa no espaço, com captação de imagens por satélites, geoprocessamento e algoritmos de IA para auxiliar na classificação e mapeamento do uso e cobertura da terra (Land Use and Land Cover – LULC).
Os dados gerados mostram a transformação do território pela sociedade e as suas características naturais, ou seja, o que existe em um lugar. Isso embasa análises geoespaciais que revelam onde as florestas permanecem, onde foram removidas e os locais em regeneração. Também alicerçam o planejamento territorial, otimizam a gestão agrícola e ambiental, subsidiam políticas públicas e contribuem para atingir os Objetivos do Desenvolvimento Sustentável.
Os limites atuais de classificação
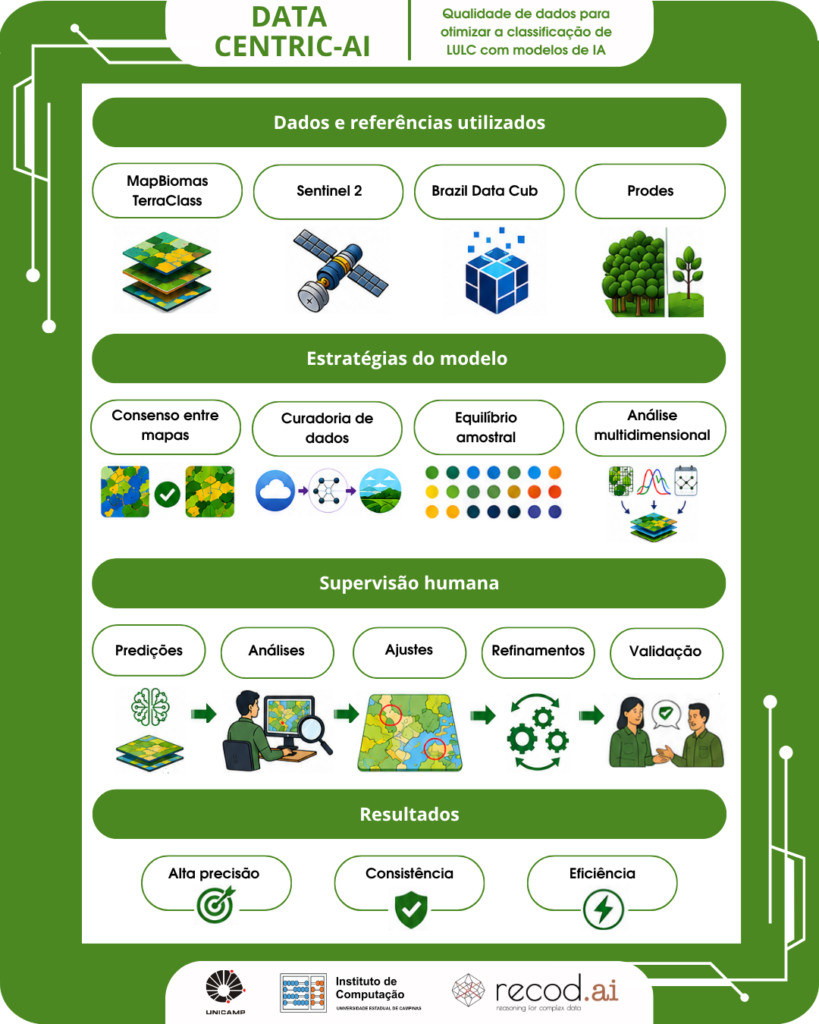
No Brasil, o mapeamento do LULC se apoia principalmente em duas iniciativas que produzem dados a partir de imagens de satélite. O MapBiomas usa imagens processadas pelo Google Earth Engine e cartografa todo o território nacional. O TerraClass utiliza o Brazil Data Cube (BDC), plataforma para observação da Terra desenvolvida pelo Instituto Nacional de Pesquisas Espaciais (INPE) e produz mapas da Amazônia e Cerrado. Embora ambas sejam consolidadas, elas usam métodos diferentes e podem apresentar divergências, mas também podem ser usadas para se estabelecer um método de rotulagem baseado na concordância entre as duas iniciativas.
A complexidade desta tarefa é inerente ao problema de se diferenciar paisagens tão heterogêneas, as quais, muitas vezes, não têm limites e características tão claros. Fatores técnicos também afetam a qualidade da classificação. As nuvens e suas sombras nas imagens de satélite criam lacunas de informação. Também há um desequilíbrio de categorias que faz com que os sistemas favoreçam classes dominantes que ocupam grandes extensões, como pastagens, em detrimento de áreas menores e menos representadas. Expandir o que o modelo aprendeu em uma região para nível nacional ainda é desafiador, pois o Brasil possui dimensão continental, e grande diversidade ambiental e climática.
A aposta na qualidade dos dados
Para superar esses desafios, as equipes da Embrapa e do Recod.ai desenvolveram uma abordagem de IA Centrada em Dados (Data-Centric AI), no contexto do projeto TerraClass. A ideia é gerar mapas mais precisos e consistentes, buscando melhor desempenho dos modelos de aprendizado de máquina. Isso é feito por meio de maior qualidade nos dados, invés de se concentrar esforços apenas na otimização de código e da arquitetura dos modelos utilizados.

O modelo foi empregado para categorizar automaticamente diferentes classes do LULC. “Quando falo de classes, estou falando de agricultura de um ciclo ou de dois ciclos, pastagem herbácea ou arbórea, água, floresta primária ou secundária, enfim. É preciso detalhar mais essas classes, porque eu não quero saber só se tem agricultura, quero saber qual é a cultura”, diz Glauber José Vaz, pesquisador da Embrapa Agricultura Digital e doutorando no Recod.ai da Unicamp. Com isso, ele aponta para a necessidade de se detalhar mais os mapeamentos existentes em pesquisas futuras.
“O MapBiomas e o TerraClass normalmente usam mais ou menos as mesmas classes, mas também têm diferenças em como consideram cada uma delas. Quando comecei a investigar isso, entendi toda a complexidade envolvida e que a gente tem que analisar os dados para entender o que acontece. Para criar o modelo, a gente precisa entender muito bem as características daquilo com que a gente está trabalhando”, completa Vaz.
O funcionamento
O estudo integrou dados de diferentes plataformas e programas para LULC. O MapBiomas e TerraClass foram usados como mapas de referência e rotulagem para cada tipo de classe. As imagens de satélite vieram do Sentinel-2, que foram organizadas e processadas pelo BDC. O PRODES, sistema de monitoramento do INPE, foi usado para diferenciar vegetação nativa de áreas desmatadas.
Crédito: Juliana Vicentini
O método foi testado na Bacia do Alto Paraguai. Essa é uma área de alta complexidade, localizada em uma zona de transição entre biomas que conta com diferentes tipos de cobertura e uso da terra. A análise foi feita em dados de 2018, “pela disponibilidade das imagens do Sentinel-2 e por ter mapas consolidados do TerraClass e do MapBiomas”, explica o pesquisador.
Uma das estratégias incorporadas no método foi a criação de rótulos por consenso, como se estabelecesse um acordo entre fontes confiáveis. Nessa lógica, o método identificou classes em que os mapas do MapBiomas e TerraClass concordavam, para a partir disso, reduzir as inconsistências, atingindo mais de 97% de precisão na rotulagem.
A curadoria de dados foi uma etapa de limpeza para remover observações inválidas, como nuvens e suas sombras. As lacunas geradas foram preenchidas por interpolação linear, técnica que estima valores intermediários com base em observações válidas anteriores e posteriores. Isso criou transições graduais nas imagens e garantiu séries temporais contínuas para o treinamento do modelo.
Para evitar que o sistema ignorasse áreas menores como as urbanizadas, os cientistas utilizaram o equilíbrio amostral. O modelo foi treinado com um número equivalente de exemplos para cada categoria. Isso impediu que áreas dominantes, aquelas que ocupam grande espaço no território, como as pastagens, prevalecessem no aprendizado de máquina.
A metodologia permitiu ao sistema analisar padrões espaciais e temporais para distinguir as classes. “Amostras multidimensionais não são comuns. O que eu vejo nos trabalhos é classificação de imagens, que não envolve a evolução no tempo, ou de séries temporais de pixels, que não considera sua vizinhança espacial no modelo. Mas tanto a vizinhança espacial, quanto a temporal são determinantes na classificação. Por isso, a importância de tratar essas dimensões ao mesmo tempo no modelo”, afirma Glauber.
IA com validação de especialistas
O pesquisador explicou que o “TerraClass é baseado na ideia de que, quem vai dar o mapa final são especialistas que vão checar todo esse mapa e editar quando for necessário”. Essa lógica também ocorre com o uso de uma abordagem centrada em dados, porque embora o modelo tenha alta precisão, ele não atua de forma autônoma e é supervisionado por humanos. “A análise dos dados, a avaliação da representatividade das amostras de treinamento e a validação dos mapas são apoiadas pelos especialistas da área”, completa o doutorando.
Próximos passos
O especialista da Embrapa Agricultura Digital ainda acrescentou que “hoje a gente fala em classe de agricultura permanente, mas não fala se é café ou laranja. Fala que é agricultura temporária, mas não fala se é soja ou algodão. Esse é um passo importante para dar no futuro”.
O projeto quer aumentar o recorte temporal, treinando o modelo com dados de anos anteriores, como 2020 e 2022, para classificar anos subsequentes. Também deseja ampliar a área de estudo de uma escala regional para um bioma, como Amazônia e Cerrado.
O modelo está em fase experimental. A equipe do TerraClass “tem um protocolo próprio já muito bem definido ao longo do tempo. Então, eu preciso de alguma maneira casar o que é feito atualmente com a nossa proposta. Para mim, isso aponta para o futuro”, finalizou o pesquisador.
Para saber mais, acesse os anais do XXV ISPRS Congress, disponíveis a partir de julho/2026.
_____
Material produzido com o apoio da Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP), Brasil (Processo nº 2025/26523-7), vinculado ao Projeto Horus do Recod.ai (Processo nº 23/12865-8).