Por Juliana Vicentini
A base reúne milhões de postagens dentro do contexto de infodemia que oferecem subsídios para a compreensão e enfrentamento da queda da cobertura vacinal no Brasil
Pesquisadores do laboratório de inteligência artificial Recod.ai criaram um banco de dados aberto para suprir a escassez de dados sobre a infodemia na área de saúde no Brasil. Disponível no Repositório de Dados da Unicamp, ele possui acesso livre para pesquisadores, desde que não haja uso comercial. Detalhes sobre essa iniciativa estão disponíveis no preprint depositado no Arxiv em processo de submissão para a revista Scientific Data – Nature.
Banco de dados em números
O conjunto de dados é robusto. Ele reúne um volume de elementos que ocupam 5,5 TB (terabytes) de armazenamento. São quatro milhões de postagens e mais de 1,4 milhão de peças de mídia que incluem imagens, vídeos, áudios e enquetes. Esses conteúdos foram postados por 71.672 usuários anonimizados, pertencentes a 119 grupos no aplicativo de mensagens Telegram.
O tamanho e a diversidade do material coletado impressionam, mas não atrapalharam a condução da pesquisa. “O volume de dados foi bem alto para outros datasets similares que são publicamente disponíveis. No entanto, essa não foi uma grande dificuldade, pois a capacidade de processamento de dados e armazenamento do cluster do Recod.ai foi robusta o suficiente para viabilizar o trabalho”, relata Leopoldo Lusquino Filho, colaborador do Recod.ai e docente da Unesp.
Narrativas no Telegram e hesitação vacinal
Há 407.723 mensagens relacionadas à antivacina, o que corresponde a 10,2% das postagens que compõem o banco de dados. As narrativas de infodemia postadas por usuários do Telegram são múltiplas e vão além da área da saúde, indicando que elas se tornaram campo de disputas ideológicas. Os temas abordados permeiam domínios da saúde e ciência, instituições e políticas públicas, crenças e desconfiança, e disputa política.
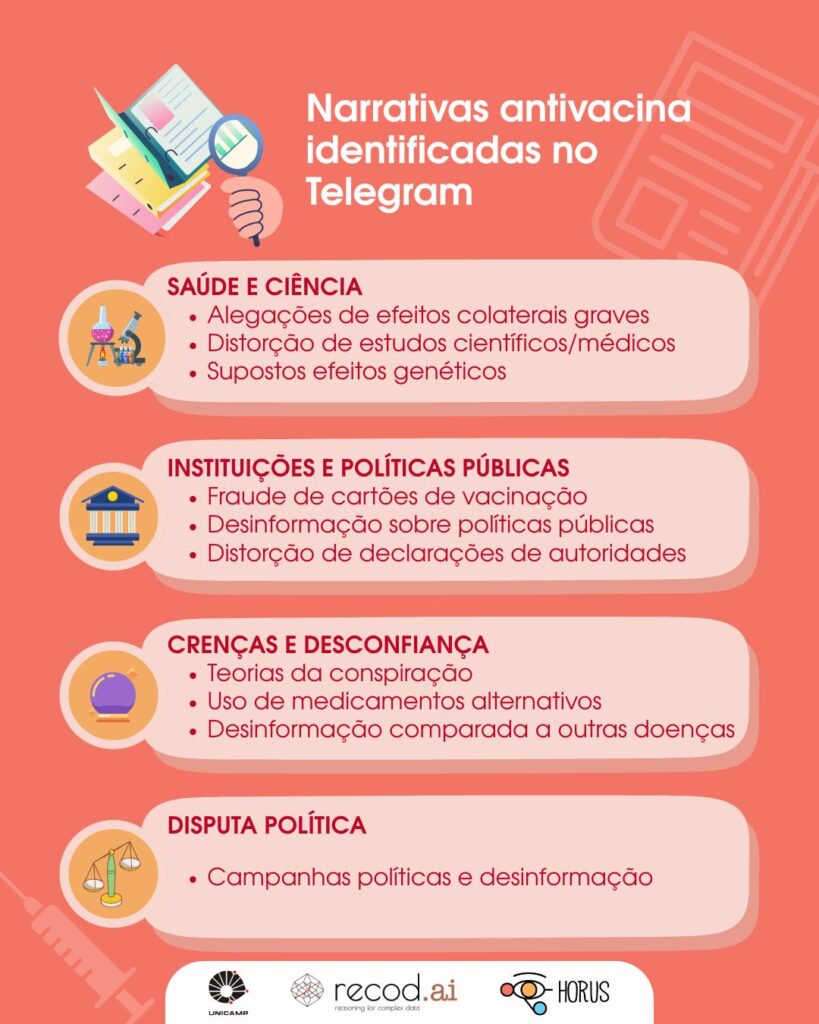
Créditos: Juliana Vicentini
A presença massiva dessas narrativas indica que a desinformação na área de saúde deixou de ser um fenômeno de comunicação e passou a ter efeitos concretos para a população. Esse tipo de conteúdo trouxe consigo impactos na política pública de vacinação, como o Programa Nacional de Imunizações (PNI). Ele foi instituído para garantir às pessoas o acesso universal e gratuito para as vacinas recomendadas pela Organização Mundial da Saúde (OMS). Criado em 1973, o PNI chegou a 75% de cobertura vacinal em 2020, apurou o Instituto Butantan. Essa foi a menor porcentagem de imunização desde o surgimento do programa e este cenário negativo está relacionado à desinformação.
Nesse contexto, a hesitação vacinal que é o atraso na aceitação ou a recusa em vacinar-se, segundo a OMS, ganhou força no território brasileiro, sobretudo nos tempos da pandemia de Covid-19. Esse comportamento foi agravado pela infodemia, que é o excesso de informações falsas ou enganosas que circulam nas plataformas digitais, como redes sociais, gerando desinformação.
A infodemia tem se mostrado um recurso crescente que influencia no comportamento vacinal. Apesar disso, dados sistematizados sobre os conteúdos antivacina nas redes sociais no Brasil ainda são escassos. O banco de dados dos pesquisadores do Recod.ai vem para apoiar as comunidades científica e de saúde no desenvolvimento de estratégias para mitigar a desinformação e a hesitação vacinal com base em evidências. O entendimento dos padrões da infodemia é essencial para reconstruir o diálogo e a confiança com pessoas afetadas por narrativas falsas.
As mais diversas áreas de pesquisa podem se beneficiar dos dados coletados, dentre elas, destacam-se: Processamento de Linguagem Natural – para entender grandes volumes de postagens; Ciências Sociais – que permite compreender as narrativas antivacina; Análise de Redes – identificar grupos e perfis influentes na disseminação de desinformação; Realidades Sintéticas – para identificar vídeos e imagens gerados por IA para apoiar discursos antivacina.
Percurso para a composição do banco de dados
O banco de dados reúne indicadores que mapeiam a infodemia no Brasil em uma plataforma de comunicação, no período de janeiro de 2020 a junho de 2025. O Telegram foi escolhido para análise porque permite uma coleta de dados ética e acessível para fins de pesquisa científica. O recorte temporal teve início na Covid-19 e se estendeu pós-pandemia, período de considerável circulação de desinformação na área de saúde.
O primeiro passo para criar o banco de dados foi identificar os principais boatos sobre vacinas em artigos de agências de checagem de fatos. A partir disso, os pesquisadores selecionaram canais e grupos no Telegram já conhecidos por disseminar conteúdos antivacina. Isso foi feito com base em palavras-chave comuns nesse meio e de recomendações do algoritmo da própria plataforma para encontrar canais públicos semelhantes com mais de mil membros.
Na sequência, os cientistas desenvolveram uma ferramenta de coleta de dados personalizada nos canais e grupos. Os conteúdos selecionados englobam textos, fotos, vídeos, áudios e enquetes. Depois do processo de coleta, os dados passaram por uma curadoria. Além disso, o projeto contou a parceria da empresa Maritaca.ai para uso do modelo Sabiá, que facilitou a identificação de postagens relacionadas a vacinação.
A privacidade dos usuários dos canais e grupos também foi assegurada. Eles passaram por um processo de anonimização, no qual nome e identificação (ID) foram removidos. Somado a isso, informações pessoais como telefone, e-mail, e entradas e saídas do grupo também foram excluídas. Isso tudo para que o processo fosse ao encontro das boas práticas de ética em pesquisa e proteção de dados, e para reduzir o risco de reidentificação dos usuários.
A metodologia desenvolvida para a criação do banco de dados é robusta. Ela é uma combinação de procedimentos de coleta, limpeza e validação. O maior desafio “foi garantir que o dataset não ficasse repleto de ruídos e lixo, o que é muito comum com este tipo de dado, para que o dataset preservasse consistência semântica e se mantivesse útil para as nossas análises e para a comunidade. Uma dificuldade maior foi relacionada a preservar uma alta taxa de coleta de dados sem violar as diretrizes das plataformas”, explica Lusquino.
Próximos passos
Em uma nova etapa do trabalho, os pesquisadores vão além da identificação das mensagens antivacina. Eles querem compreender o que leva as pessoas a circularem e a aderirem a esse tipo de conteúdo. “Existem muitas motivações para o consumo e propagação das narrativas antivacina, então, estamos nos baseando em algumas taxonomias sobre hesitação vacinal na literatura para anotar nossos dados com essas informações. Como elas não são exaustivas, precisamos pensar novas categorias de motivação e criar um processo de anotação eficiente de acordo com essa taxonomia expandida. Isso tem sido um tanto quanto complexo, ainda está em andamento e os resultados dele estarão disponíveis em uma segunda versão do nosso dataset”, revela, em primeira mão, o pesquisador.
O banco de dados é resultado de uma parceria entre o Recod.ai e a Maritaca.ai. que, juntos, reúnem expertises acadêmicas e tecnológicas no desenvolvimento de soluções baseadas em IA. O apoio financeiro é da Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP) por meio do Projeto Horus, Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq) e Ministério da Saúde – a partir do Projeto Aletheia.
____
Reportagem produzida com o apoio da Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP), Brasil (Processo nº 2025/26523-7).